


Knowing your data is critical if you’re looking to implement robust data protection policies and practices. Microsoft Purview gives you the power to make sense of the data in your tenant. In this practical guide, technology architecture expert Paul Westlake explains how to use this tool to get the full picture of your data.
Data is one of the most important assets any organisation owns – and the more of it there is, the more important it is to manage effectively.
Many organisations start their data protection policy with one of three things: sensitivity labels, retention labels or data loss prevention. While these are all good starting points, at Advania we believe that knowing your data should come before all else and will help you make informed decisions about your data governance.
This blog will explore the first of four aspects of Microsoft’s recommended data lifecycle approach: knowing your data. We’ll demonstrate how this enables you to make informed decisions in the subsequent stages.
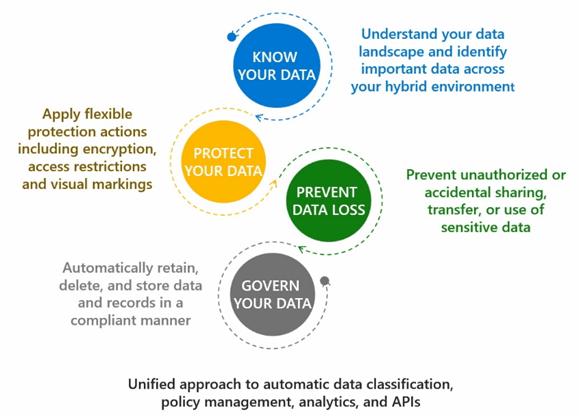
What is Microsoft Purview? Your tool for knowing your data
Microsoft Purview is a data governance, risk and compliance product suite, combining the former Azure Purview and Microsoft 365’s compliance solutions into one comprehensive product. Microsoft Purview secures your organisation’s data by:
- providing visibility into your data assets;
- giving you access to data, security and risk solutions;
- safeguarding and managing sensitive data across clouds and apps;
- managing end-to-end data risks and regulatory compliance;
- providing you with new ways to govern, protect and manage data.
The importance of data classification
Having your data stored across a Microsoft 365 tenant means that leveraging Microsoft Purview to identify and classify it is straightforward. By default, Microsoft Purview will review all the unstructured data in your tenant and look for sensitive information, and surface statistics for it in its admin centre’s data classification tool.
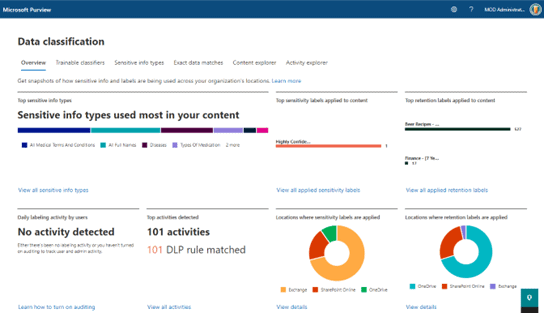
Here you can see a summary of the sensitive content, where it’s located, as well as how sensitivity and retention labels are being used across your organisation.
You can view the types of sensitive data Microsoft Purview has identified in files within the ‘content explorer’ tool in your organisation’s tenant. This is where we can start to build a picture on the types of data to start protecting.
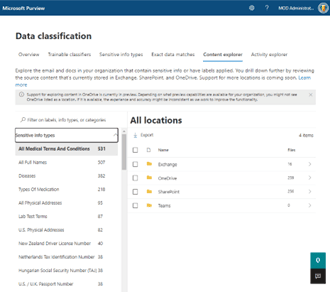
If you have started to use sensitivity and/or retention labels you will see their usage counts here. More recently, and if you have enabled the feature, Microsoft has begun to elevate details from trainable classifiers (E5 licence is required) in the content explorer.
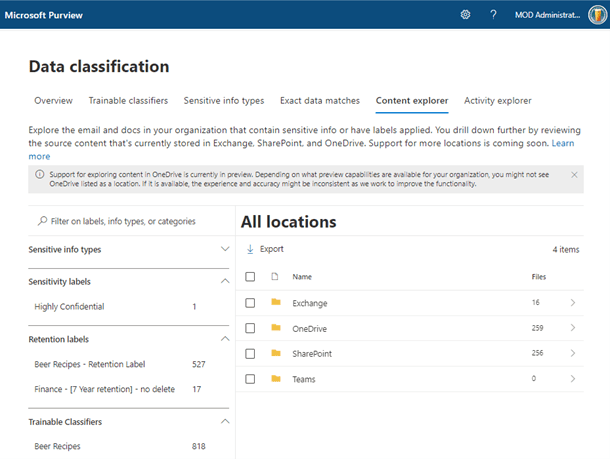
With the right permissions, you can drill down to the actual data that’s useful for information governance and risk teams, enabling them to verify the sensitivity type or if it is a false positive.
What is classified as sensitive data?
There are more than 260 Microsoft-authored sensitive information types (SIT) within Microsoft Purview, covering a wide range of data types, from credit-card number formats to blood test terms. With over 70 different global regions covered, protection policies can target specific geolocations or entire regions, such as the EU for General Data Protection Regulation (GDPR).
SITs can act as templates for custom types you might want to create. They can also be used in conjunction with one another to create policies to detect regulatory sensitive data such as personally identifiable information (PII).
If, for example, your organisation uses a specific format for your client reference numbers, a custom SIT can be crafted using a regular expression. This then enables the content explorer to inform you of the amount of data containing the client number based on this SIT.
How can I easily classify unstructured data?
Where data cannot be located using structured means, such as regular expressions or keyword lists, you can use a trainable classifier to identify unstructured content.
Microsoft currently provides 17 predefined trainable classifiers to detect content such as HR, finance or healthcare material in multiple languages, including profanity and targeted harassment. These classifiers can be used in auto-labelling of retention policies, to make recommendations for or automatically apply sensitivity labels, and be defined in communication compliance policies.
Building customised trainable classifiers demonstrates the power of machine learning. Many organisations hold significant quantities of intellectual property, such as product plans or unique recipe details. Trainable classifiers are a key tool to identify this content.
Use custom trainable classifiers for deeper insights
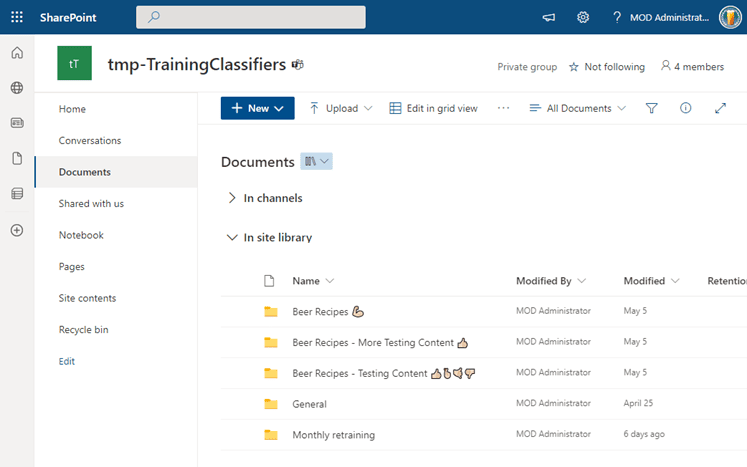
To prepare a custom trainable classifier within your own tenant, all it takes is seed data. This should be made up of at least 50 strong examples representing the type of data you want to classify, stored in a dedicated SharePoint site.
After Microsoft Purview has analysed the seed data, you can further train the classifier by adding test data with a mix of expected and unexpected content. After the data is scanned, it’s time to review the results. Each time we review 30 documents, the classifier retrains itself, adjusting its accuracy score as it goes.
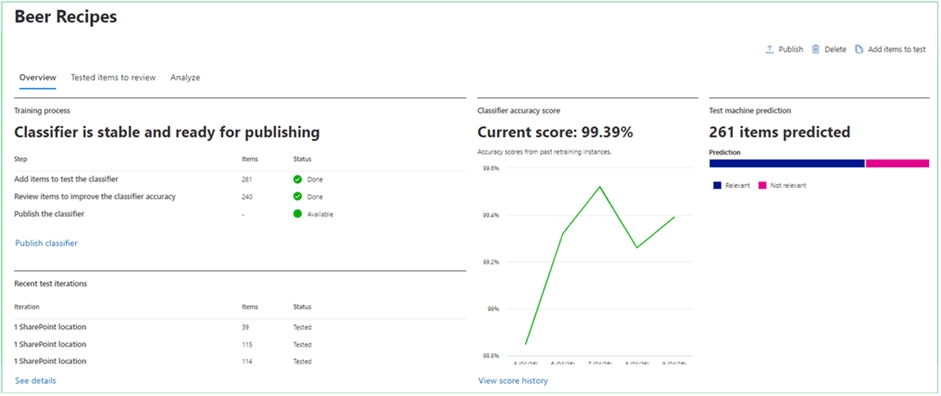
When the custom trainable classifier can recognise a strong percentage of the target data, it can be published for use in the appropriate location.
How does knowing your data protect against data loss?
When organisations think about data loss prevention (DLP), the initial thought will be to control and prevent the sharing of content outside of the organisation.
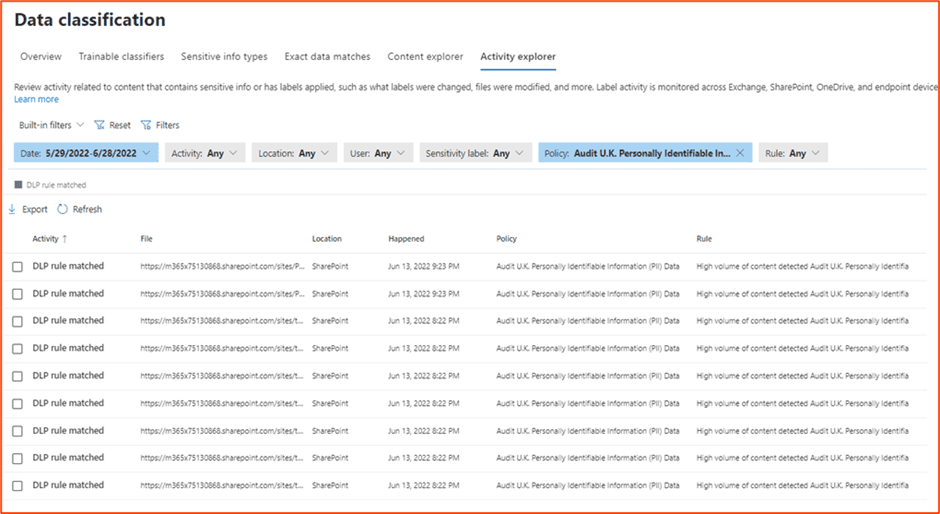
Microsoft Purview DLP gives you the key to knowing your data. You can do this through the reports generated in the activity explorer feature.
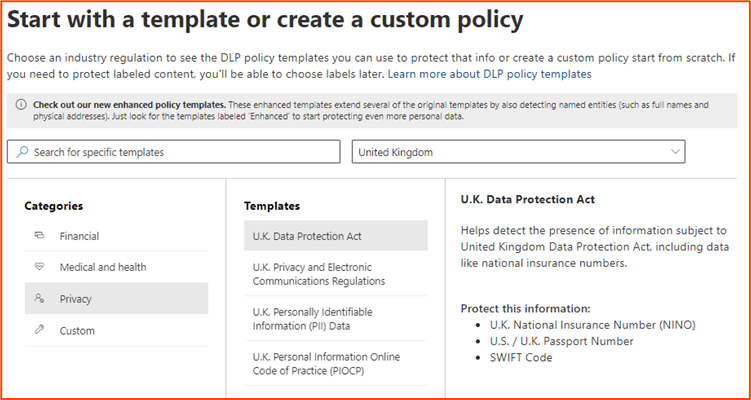
Let us assume we want to surface all the data that might relate to the UK Data Protection Act. In this case, we create a DLP rule which will audit all PII within the service.
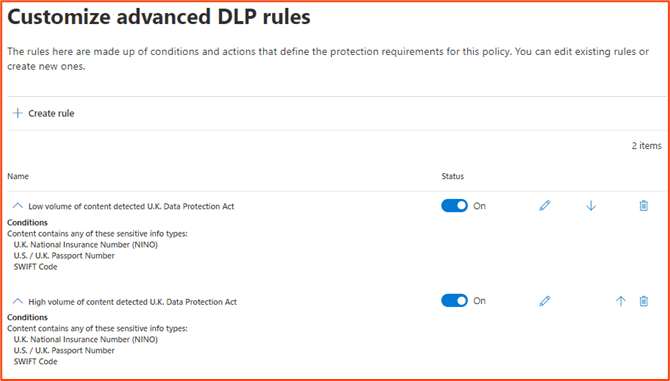
In the rules section of the policy, we can remove any actions, notifications and incident reporting, but leave the severity in place.
We can then set the policy to be enabled right away. After a while, the policy will start to generate statistics in the activity explorer. This means we can report on sensitive data as sets relating to regulatory requirements, not just individual SITs.
Leveraging this understanding to create a data protection policy
Now you have built a picture of the types of sensitive data identified across your Microsoft 365 tenant, location and quantity, you can target appropriate protections based on the results.
For example, if you have a large amount of healthcare data, you may want to implement policies for:
- sensitivity labelling to auto-label content, including encryption;
- DLP to stop content being shared externally with untrusted partners;
- retention to dispose of the content automatically after a set timeframe;
- communication compliance to monitor who is sharing content within or outside of the organisation.
All these policies and controls can be managed by either SITs or trainable classifiers. This means that you can apply protection, retention and governance policies to specific data sets, including your intellectual property.
When you know the data you hold, you’re empowered to focus on protecting that data instead of wasting energy on a data governance policy that affects end users but doesn’t protect your organisation where it counts.





